SQL DDL & DML: Aufgaben#
In diesem Tutorium üben wir die Funktionalitäten der SQL Data Description Language (DDL) und SQL Data Manipulation Language (DML). Die DDL beschreibt, welche Daten in einer Datenbank gespeichert werden. Die DML wird hingegen genutzt, um Instanzen in unserer Datenbank zu erstellen, zu verändern oder auch wieder zu löschen.
Wir benutzen hierfür die eingebettete Datenbank DuckDB, welche auch über das Python-Paket duckdb unterstützt wird. DuckDB wurde ursprünglich als Datei- oder In-Memory-basierte OLAP-Datenbank entwickelt (was OLAP heißt, sehen wir im Data Warehouse-Tutorium).
Hinweis: Aufgaben, welche durch einen Asterisk (*) markiert sind, sind Bonusaufgaben. Diese Aufgaben können im Tutorium behandelt werden, dies ist jedoch von den Übungsleitern nicht geplant.
Aufgabe 1: Geeignete Wahl von Datentypen#
Datenbanken unterstützen in der Realität nur eine limitierte Anzahl an unterschiedlichen Datentypen. Daher muss nach dem Abschluss der Modellierungsphase und der Wahl einer Datenbank-Software zunächst entschieden werden, welche Datentypen die Modellierungsergebnisse am besten abbilden.
In den folgenden drei Teilaufgaben ist jeweils eine Relation gegeben. Überlegen Sie sich zu den Attributen passende Datentypen und begründen Sie Ihre Entscheidung. Nutzen Sie dazu auch die DuckDB-Dokumentation.
Aufgabe1.1: Kunde#
Kunde_ID |
Name |
Straße |
Hausnummer |
PLZ |
Premium Kunde |
Telefonnumer |
|---|
Aufgabe 1.2: Buch#
ISBN |
Titel |
Autor |
Preis |
Veröffentlicht |
Buchcover |
Abstract |
|---|
Aufgabe 1.3: Shop*#
Kunde_ID |
ISBN |
Kaufzeitpunkt |
|---|
Aufgabe 2: Eigenschaften von Datentypen#
Gegeben ist eine Tabelle mit vielen Attributen. Testen Sie das Verhalten von diversen Datentypen in DuckDB, welches Verhalten ist nachvollziehbar und welches Verhalten ist überraschend?
import duckdb
con = duckdb.connect()
con.sql(
"""
CREATE TABLE Getraenk (GetränkeId BIGINT PRIMARY KEY,
Preis DECIMAL(8,2),
Pfand float,
Marke VARCHAR(20),
BarcodeNummer INTEGER);
"""
)
con.sql("INSERT INTO Getraenk VALUES (1, 1.29, 0.15, 'Club-Mate', NULL)")
con.sql("")
con.close()
Aufgabe 3: Tabellen#
Im nächsten Schritt implementieren Sie nun ein vollständiges Datenbankschema. Beachten Sie auch hierzu im Zweifel wieder die DuckDB Dokumentation.
Als Erstes erstellen wir eine Datenbank im Arbeitsspeicher:
con = duckdb.connect()
Gegeben sei das folgende ER-Diagramm. In den folgenden Teilaufgaben schreiben Sie für jede Relation eine DDL-Query, welche die entsprechende Tabelle erstellt. Überlegen Sie dabei jeweils vorher für die Attribute geeignete Datentypen und ggf. weitere Integritätsbedingungen.

Aufgabe 3.1#
Wie viele Tabellen müssen Sie minimal für das obenstehende Schema erstellen? Erstellen Sie den relationalen Entwurf zu diesen Tabellen.
Aufgabe 3.2#
Erstellen Sie die Tabelle Fakultaet. Integrieren Sie dabei die Anforderung, dass diese Tabelle nur die Fakultäten der TU Berlin enthalten darf (d. h. es gibt sieben Fakultäten, welche mit römischen Zahlen bezeichnet werden).
query = """
"""
con.sql(query)
Aufgabe 3.3#
Erstellen Sie nun die Tabelle Pruefungsfach.
query = """
"""
con.sql(query)
Aufgabe 3.4#
Erstellen Sie nun die Tabelle Student. Es gibt die zusätzliche Anforderung, dass Studierende in der Vergangenheit geboren sein müssen.
query = """
"""
con.sql(query)
Aufgabe 3.5#
Erstellen Sie nun zuletzt ein paar beispielhafte Instanzen und fügen Sie diese in die Tabellen ein. Um das Ergebnis zu prüfen, haben wir für Sie bereits drei SQL-Statements vorbereitet, welche den Inhalt der Tabellen ausgeben.
query = """
"""
con.sql(query)
con.sql("SELECT * FROM Fakultaet")
---------------------------------------------------------------------------
CatalogException Traceback (most recent call last)
Cell In[9], line 1
----> 1 con.sql("SELECT * FROM Fakultaet")
CatalogException: Catalog Error: Table with name Fakultaet does not exist!
Did you mean "duckdb_databases"?
con.sql("SELECT * FROM Student")
con.sql("SELECT * FROM Pruefungsfach")
Aufgabe 3.6#
Löschen Sie nun eine Instanz der Relation Fakultaet, welche von Instanzen der Relationen Pruefungsfach oder Student referenziert wird. Um diese löschen zu können, muss mehr gelöscht werden als nur diese eine Instanz. Warum? Zum Überprüfen des Ergebnisses haben wir erneut drei SQL-Statements zum Ausgeben der Tabellen vorbereitet.
query = """
"""
con.sql(query)
con.sql("SELECT * FROM Fakultaet")
con.sql("SELECT * FROM Student")
con.sql("SELECT * FROM Pruefungsfach")
Aufgabe 3.7#
Erstellen Sie nun die Tabelle belegt. Es soll sichergestellt sein, dass nur Hochschulnoten eingetragen werden können. Eine Note mit dem Wert 1.5 sollte man also z.B. nicht eintragen können, die Note 1.7 aber schon (vgl. § 68 (1) AllgStuPO).
query = """
"""
con.sql(query)
Aufgabe 3.8#
Erstellen Sie nun zuletzt ein paar beispielhafte Instanzen in der Relation belegt und testen Sie die Integritätsbedingung für Noten. Zum Überprüfen des Ergebnisses haben wir erneut ein SQL-Statement zum Ausgeben der Tabelle vorbereitet.
query = """
"""
con.sql(query)
con.sql("SELECT * FROM belegt")
con.close()
Aufgabe 4: Schemata*#
In der folgenden Aufgabe setzten wir uns mit Datenbankschemata auseinander. Ein Datenbankschema besteht aus mehreren Tabellen und beschreibt damit ein zusammenhängendes Informations-Konstrukt. In Produktiv-Datenbankmanagementsystemen werden Datenbankschemata im Mehrbenutzer:innen-Betrieb genutzt, um den Zugriff auf Daten zu beschränken. In der Datenbank eines Online-Shops sollen bspw. Kund:innen zwar Produkte einsehen können, aber nicht, wie viele Produkte noch auf Lager sind, oder wie die anderen Kund:innen des Shops heißen und wo sie wohnen. Die Angestellten-Datenbank, welche vom selben Datenbankmanagementsystem verwaltet wird, ist dann ein weiteres Datenbankschema und komplett getrennt vom Shopsystem.
Im Folgenden definieren wir auf einem einfachen Niveau derartige Schemata. Wir nutzen für diese Aufgaben wieder die DuckDB Dokumentation.
Zuerst erstellen wir eine Datenbank im Arbeitsspeicher für die Bearbeitung der Aufgabe.
con = duckdb.connect()
Aufgabe 4.1: Schemata erstellen*#
Erstellen Sie zuerst ein Schema mit dem Namen internesSchema.
Hinweis: Das aktive Schema können Sie mittels SET search_path TO <schemaName> wechseln. Alternativ können Sie mithilfe der Punktnotation das Schema in Kombination mit der Tabelle angeben, um zu spezifizieren, welche Relation oder Instanzen Sie referenzieren möchten.
con.sql("")
4.2: Schema füllen*#
Erstellen Sie nun die folgende Tabelle für internesSchema.
Produkt(ProduktId, Produktname, Produktbeschreibung, Preis, Haeufigkeit)
con.sql("")
4.3: Tabelle Füllen*#
Füllen Sie nun die Tabelle mit ein paar beispielhaften Instanzen. Ein Befehl zum Ausgeben der Tabelle, damit Sie das Ergebnis überprüfen können, ist bereits vorhanden.
con.sql(
"""
"""
)
con.sql("SELECT * FROM Produkt")
4.4: Kundenschema*#
Erstellen Sie nun ein zweites Schema für die Kunden in Ihrem Online-Shop.
con.sql("")
4.5: Produkttabelle*#
Erstellen Sie nun die Produkttabelle auch für die Kunden, aber ohne die Häufigkeit, da die Lagerbestände intern bleiben sollen.
Produkt(ProduktId, Produktname, Produktbeschreibung, Preis)
Hinweis: Alternativ könnte ein solches Verhalten auch mit Views realisiert werden. Diese werden jedoch nicht in der Vorlesung behandelt, weshalb wir das Problem mit zwei sehr ähnlichen Tabellen in zwei Schemata lösen.
con.sql(
"""
"""
)
con.sql("SELECT * FROM kundenSchema.Produkt")
4.6: Datenübertragen*#
Übertragen Sie nun zuletzt die Daten von internesSchema.Produkt nach kundenSchema.Produkt, aber nur die Daten, welche die Kunden auch einsehen sollen.
con.sql(
"""
"""
)
con.sql("SELECT * FROM kundenSchema.Produkt")
con.close()
Aufgabe 5: Regatta*#
In dieser Aufgabe führen wir das vorab gelernte zusammen und implementieren eine Datenbank für ein Regatta-Informationssystem.
Hinweis: Diese Regatta-Datenbank werden wir im Laufe des Semesters noch wiederholt sehen.
Gegeben seien folgende Relationen:
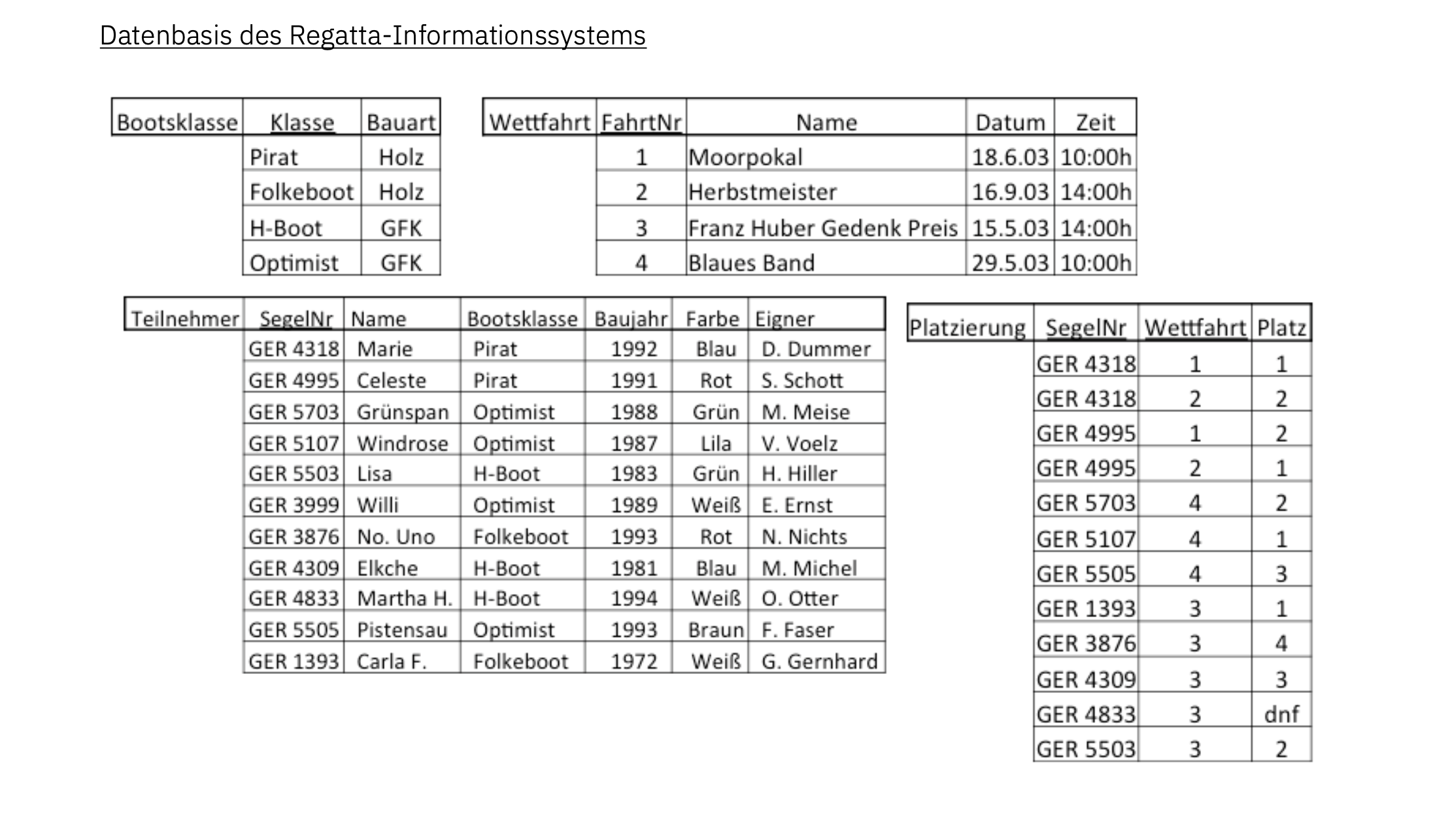
Im Folgenden wollen wir zu jeder Relation eine Tabelle erstellen und in diese die zugehörigen Tupel einfügen. Zuerst erstellen wir erneut eine Datenbank für die Aufgabe.
con = duckdb.connect("regatta.duckdb")
Entwerfen Sie die notwendigen CREATE TABLE und INSERT Ausdrücke, um die Datenbank wie im Diagramm abgebildet zu erstellen. Trennen Sie dabei die einzelnen Ausdrücke durch ein Semikolon.
Hinweis: Kodieren Sie die Platzierung dnf als NULL.
query = """
your query here
"""
con.sql(query)
Prüfen Sie abschließend das Ergebnis.
con.sql("SELECT * FROM Bootsklasse")
con.sql("SELECT * FROM Wettfahrt")
con.sql("SELECT * FROM Teilnehmer")
con.sql("SELECT * FROM Platzierung")
con.close()