Data Warehousing: Aufgaben (Lösungen)#
Aufgabe 1#
Gegeben sind die unten stehenden Anwendungsszenarien; kategorisieren Sie diese als OLAP- oder OLTP-Anfragen?
Kassenverwaltung im Supermarkt.
Auswirkung von Werbekampagnen auf Verkaufszahlen bestimmen.
Ticketwebseite für Konzerte.
Überwachung des Flugraums (Fluglotsen).
Identifizieren der wichtigsten Kunden.
„Wird oft zusammen gekauft“ (z.B. bei Amazon).
Musterlösung
Musterlösung
Kassenverwaltung im Supermarkt. (OLTP: Verkäufe sind Transaktionen)
Auswirkung von Werbekampagnen auf Verkaufszahlen bestimmen. (OLAP: Vergleich von Verkaufsdaten vor & nach der Kampagne)
Ticketwebseite für Konzerte. (OLTP: Ticketverkäufe sind Transaktionen)
Überwachung des Flugraums (Fluglotsen). (OLTP: Viele transaktionale Updates (Flugzeugpositionen), OLAP: Analytische Anfragen zur Überwachung des Flugraums) (Die Unterscheidung von OLAP und OLTP ist nicht immer eindeutig)
Identifizieren der wichtigsten Kunden. (OLAP: Untersuchung von Verkaufsdaten)
„Wird oft zusammen gekauft“ (z.B. bei Amazon). (OLAP: Untersuchung von Verkaufsdaten)
Aufgabe 2#
Gegeben sei der folgende OLAP Würfel

Der Würfel beschreibt die Clickstream-Datenbank. Diese ist eine einfache Datenbank, welche eine Aufzeichnung der von einem Benutzer auf einer Website getätigten Klicks speichert.
Eine solche Datenbank kann zum Beispiel benutzt werden für:
Marketing
Click Fraud Detection
Verbesserung des Websitedesigns
Für die Modellierungen gelten die folgenden Eigenschaften:
Dimensionen: Page, User, Session
Eine Zelle beschreibt eine Zusammenfassung der Klicks, die ein bestimmter Nutzer in einer bestimmten Session auf einer bestimmten Page getätigt hat.
Beachte: Logische Repräsentation, die meisten Zellen sind leer!
User haben die folgenden Attribute:
Name, Email, Alter, Adresse, Kreditkartennummer, Kreditkarteninhaber, Kreditkartenablaufdatum,
Session hat die folgenden Attribute:
Sessionstart, Sessionende, IP, Browsertyp, Browserversion, Betriebssystem
Page hat die folgenden Attribute:
Seitenname, Seitendomain, Seitensubdomain
Aufgabe 2.1 Modellierung#
Im Folgenden modellieren Sie die Klicks mittels aller drei Schemata, welche Sie in diesem Modul zu Data Warehousing kennengelernt haben.
Aufgabe 2.1.1: Sternschema#
Modellieren Sie die Klicks in einem Sternschema.
Musterlösung
Musterlösung
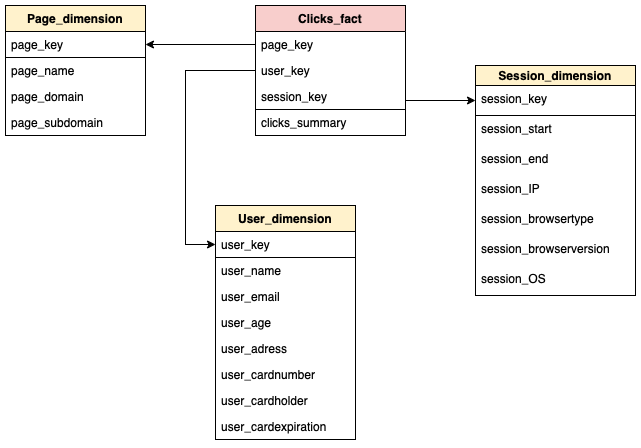
Unbedingt diskutieren:
wie viele Relationen werden benöigt
welche Daten bzw. Attribute sollen in diesen Relationen stehen
Aufgabe 2.1.2: Schneeflockenschema#
Modellieren Sie die Klicks in einem Schneeflockenschema.
Musterlösung
Musterlösung
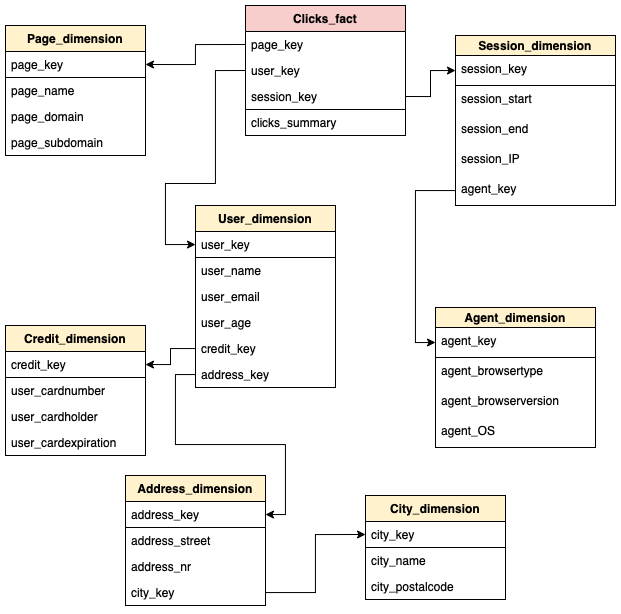
Aufgabe 2.1.2: Fullfact-Schema#
Modellieren Sie die Klicks in einem Fullfact-Schema.
Musterlösung
Musterlösung
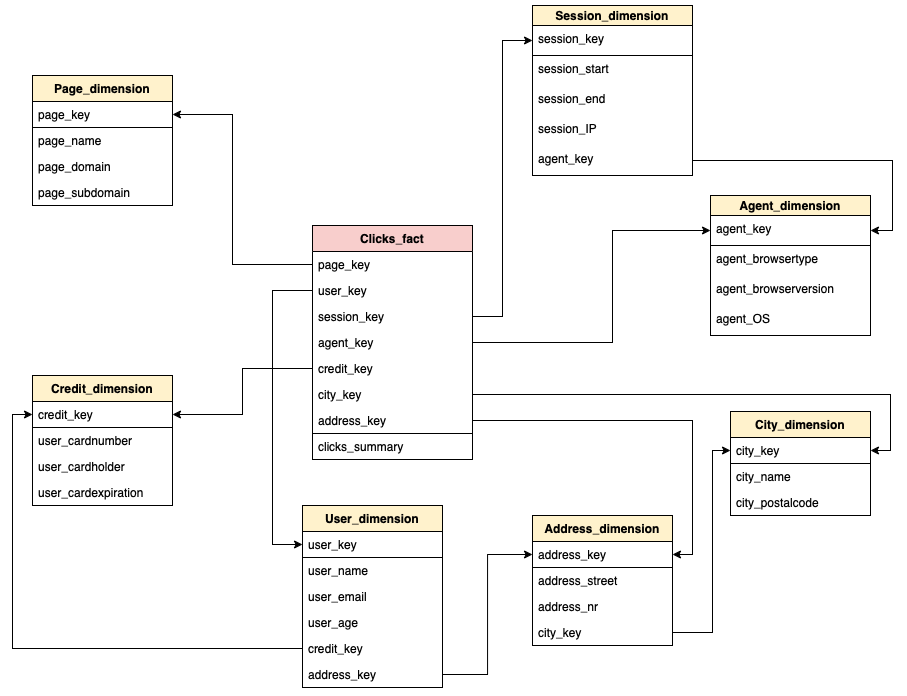
Aufgabe 2.2 Vergleich der Schemata#
Wie viele Joins benötigen wir in jedem Schema, um für alle Nutzer aus Berlin, die am 21.06.21 auf der Seite dima.tu-berlin.de waren, die Daten auszuwerten?
Musterlösung
Musterlösung
Star 3
tabellen : facts, page, session, user
Snowflake 5
tabellen : facts, page, user, adress, city, session
Fullfact 3
tabellen : facts, page, session, city
Aufgabe 2.3#
Was sind die Vorteile und Nachteile der jeweiligen Schemata?
Musterlösung
Musterlösung
Star
Vorteile:
flexibel, wenige Joins
OLAP Anfragen können als einfache SQL-Anfragen modelliert werden.
Nachteil:
Dimensionstabellen sind denormalisiert
Probleme bei ändernden Dimensionen
Snowflake
Vorteile:
sehr strukturiert, wenig Speicherplatz
robust gegen verändernde Dimensionen
Nachteil:
viele Joins, sehr langsam
Fullfact
Vorteile:
kombiniert Vorteile von Star und Snowflake
Nachteil:
sehr hoher Speicherbedarf
Aufgabe 3#
Gegeben sei das folgende Sternschema zum Modellieren einer Verkaufsdatenbank aus dem Star-Schema-Benchmark.
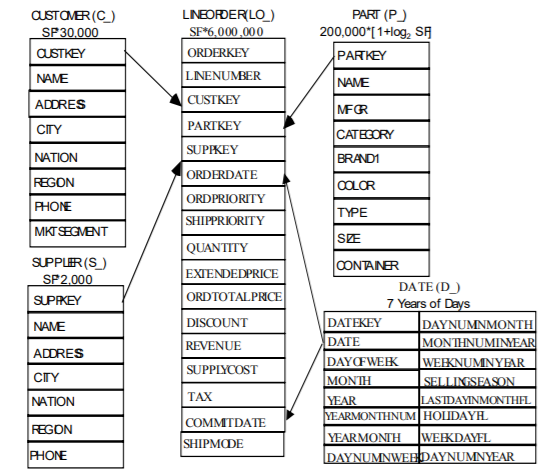
Dieser OLAP-Würfel hat 5 Dimensionen, die als Dimensionstabellen modelliert sind: Customer, Supplier, Part sowie Orderdate und Commitdate.
Außerdem gibt es noch weitere Dimensionen, die direkt in der Faktentabelle modelliert sind, z.B. orderpriority und shippriority.
Als Erstes laden wir die Beispieldatenbank:
import duckdb
con = duckdb.connect(database="resources/08_data_warehousing/ssb.duckdb", read_only=False)
---------------------------------------------------------------------------
IOException Traceback (most recent call last)
Cell In[1], line 3
1 import duckdb
----> 3 con = duckdb.connect(database="resources/08_data_warehousing/ssb.duckdb", read_only=False)
IOException: IO Error: Cannot open file "/builds/dima/isda/isda-sose25/08_data_warehousing/resources/08_data_warehousing/ssb.duckdb": No such file or directory
Zuerst testen wir die Datenbankverbindung, indem wir die Anzahl der Einträge in der Faktentabelle zählen.
query = """
SELECT count(*)
FROM lineorder
"""
con.execute(query).fetchdf()
Aufgabe 3.1: Drill down mittels Dicing und Slicing#
Die Faktentabelle enthält ca. 60000 Zeilen. Jeder Eintrag ist ein einzelner Bestellposten.
(Ein Bestellposten ist Teil einer Bestellung und besteht unter anderem aus einem Produkt und der Anzahl des Produkts. Stellen Sie sich eine Rechnung eines Gemüsehändlers vor, mit 10 Äpfeln und 20 Birnen. Dann sind z.B. die 10 Äpfel ein Bestellposten, d.h., 1 Eintrag in der Faktentabelle.)
Die Datenbank enthält nur Bestellungen aus dem Januar 1992.
Im Folgenden führen wir ein Drill down mittels Dicing und Slicing durch.
Zuerst führen wir ein Dicing durch. Wir erstellen einen OLAP-Würfel, der den Umsatz (revenue) gruppiert nach Jahr des Bestelldatums und der die Herkunftsregion der Käufer beinhaltet.
query = """
SELECT year, region, sum(revenue)
FROM lineorder l
JOIN date d ON (l.orderdate = d.datekey)
JOIN customer c ON (l.custkey = c.custkey)
GROUP BY year, region
"""
con.execute(query).fetchdf()
Der OLAP-Würfel hat 2 Dimensionen: Bestelldatum und Käufer. Die Granularität der Bestelldatum-Dimension ist Jahr und die Granularität der Käufer-Dimension ist Region.
Granularität: Granularität bezieht sich auf das Detailniveau, auf dem Daten analysiert oder gespeichert werden, und bestimmt das Maß an Spezifität oder Aggregationsgrad der Daten.
Aufgabe 3.1.1: Dicing#
Erstellen Sie einen OLAP-Würel, der den Umsatz der Bestellungen gruppiert nach Jahr, Monat und Wochentag (dayofweek) und nach dem Land der Käufer gruppiert ist.
Wie viele Dimensionen hat dieser OLAP-Würel?
Was ist die Granularität der Dimensionen?
query = """
"""
con.execute(query).fetchdf()
Musterlösung
Musterlösung
Der OLAP-Würfel hat weiterhin 2 Dimensionen (orderdate und customer). Die Attribute year, month, dayofweek gehören alle zur Dimension orderdate.
Die Granularität ist dayofweek und nation.
Aufgabe 3.1.2: Slicing#
Verfeinern Sie den bestehenden OLAP-Würfel, in dem sie nur die Umsatzsummen an Dienstagen und in Europa ausgeben.
Wie viele Dimensionen hat dieser OLAP-Würfel?
Was ist die Granularität der Dimensionen?
query = """
"""
con.execute(query).fetchdf()
Musterlösung
Musterlösung
Der OLAP-Würfel hat weiterhin 2 Dimensionen (orderdate und customer). Die Attribute year, month, dayofweek gehören alle zur Dimension orderdate.
Die Granularität ist nach wie vor dayofweek und nation.
Aufgabe 3.1.3: Slicing und Dicing#
Verfeinern Sie den vorherigen OLAP-Würfel, in dem sie nur Einträge in Deutschland auswählen und gleichzeitig nach den Städten der Käufer gruppieren. Zählen Sie außerdem die Anzahl der Einträge in jeder Gruppe.
Wie viele Dimensionen hat dieser OLAP-Würfel?
Was ist die Granularität der Dimensionen?
query = """
SELECT ...
"""
con.execute(query).fetchdf()
Musterlösung
Musterlösung
Der OLAP-Würfel hat weiterhin 2 Dimensionen (orderdate und customer). Die Attribute year, month, dayofweek gehören alle zur Dimension orderdate.
Die Granularität ist nun dayofweek und city.
Aufgabe 3.1.4: Ausgabe der Werte für eine Stadt#
Geben Sie die Bestellposten aus, die an einem Dienstag in Deutschland in der Stadt ‘GERMANY 1’ (zwei Leerzeichen zwischen Germany und 1) verkauft wurden.
Es sollten ausgegeben werden:
Das Datum der Bestellung (date.date).
Der Name des Käufers.
Der Name des Produkts.
Der Umsatz (revenue).
query = """
"""
con.execute(query).fetchdf()
Aufgabe 3.1.5: Auswirkungen von Verfeinerungen auf Ergebniskardinalitäten#
Betrachten Sie nun die Slicing- und Dicing-Operationen, die wir in den vorherigen Aufgaben verwendet haben. Welche Auswirkungen haben Verfeinerungen auf die Kardinalität unserer Ergebnisrelation?
Musterlösung
Musterlösung
Eine Verfeinerung einer Slicing-Operation führt generell dazu, dass die Ergebnisrelation eine geringere Kardinalität aufweist.
Eine Verfeinerung einer Dicing-Operation führt generell dazu, dass die Ergebnisrelation eine höhere Kardinalität aufweist.
Aufgabe 3.2: CUBE und ROLLUP#
In den folgenden Teilaufgaben wenden Sie die CUBE- und ROLLUP-Operatoren an.
Aufgabe 3.2.1: CUBE-Operator#
Bestimmen Sie die Summe des Umsatzes, gruppiert nach Wochentag und Region der Kunden. Benutzen Sie den CUBE-Operator, um über mehrere Gruppensets zu gruppieren. Sortieren Sie die Anfrage nach Wochentag und Region.
Welche Gruppensets gibt es?
Wie viele Zeilen enthält die Ausgabe, wenn es 7 Wochentage und 5 Regionen gibt?
query = """
"""
con.execute(query).fetchdf()
Musterlösung
Musterlösung
Gruppensets:
Wochentag und Region
Wochentag
Region
Leere Gruppe (gruppiert über alle Einträge)
Es müsste \(7 \cdot 5 + 7 + 5 + 1 = 48\) Gruppen geben. In der Ausgabe gibt es aber nur 47 Gruppen. Am Sonntag gab es in Afrika keine Verkäufe
Aufgabe 3.2.2: CUBE-Operator nachbauen#
Wie kann das gleiche Ergebnis ohne CUBE-Operator erzeugt werden?
query = """
"""
con.execute(query).fetchdf()
Aufgabe 3.2.3: ROLLUP-Operator#
Ermitteln Sie die Summe des Umsatz gruppiert nach Region und Land. Benutzen Sie dafür den ROLLUP-Operator.
Wie viele Einträge hat das Ergebnis, wenn es 24 Länder und 5 Regionen gibt?
query = """
"""
con.execute(query).fetchdf()
Musterlösung
Musterlösung
Das Ergebnis hat \(24 + 5 + 1 = 30\) Einträge. Dies ist ein gutes Beispiel für korrelierte Daten.
Aufgabe 3.2.4: ROLLUP-Operator nachbauen#
Wie kann die Gleiche Anfrage ohne ROLLUP-Operator erzeugt werden?
query = """
"""
con.execute(query).fetchdf()
Musterlösung
Musterlösung
Der folgende Befehl schließt die Datenbank.
# Einkommentieren, falls Sie die Verbindung nicht schließen wollen
con.close()